White Paper - Big Content: Is Bigger Better or Just Bigger 617.97 KB 38 downloads
Much is made today of the concept of "Big Data." As with most new terms related to...Perhaps the most interesting part of that definition is the concept of “tolerable elapsed time” to process that data. What exactly does this mean? Tolerable seems to be subjective. For example, during an emergency, micro-seconds can seem like hours. If the results of the process are vitally important, we may be willing to wait longer for those results. The time required to process the data will depend on the processes being run against the data. And of course, it all depends on the amount of processor power available. Nowadays, people have desktop PCs, which would have been considered supercomputers 25 years ago. This is obviously a subjective criteria.
This kind of analysis is an interesting intellectual exercise, but why are organizations interested in this Big Data concept? The concept is very real. The amount of information available to us today is vast. Ninety percent of the data in the world was created within the last two years. Every day 2.2 million terabytes of new information are created.1 Organizations have invested billions of dollars in technology to create, capture, and store this information, all with the intent of giving employees, managers, and executives the information they need to make the best decisions. 
The problem is that, between the Internet, social media, computing power, always-on connectivity, processors in the palm of our hands, and cloud storage, we have gotten significantly better at one side of the equation than the other. We can create, capture, and store data; however, our ability to assimilate and exploit that data as an information asset in meaningful ways is lacking.
The discussion about Big Data is now common in today’s environment because of this explosion of data, of which a significant portion results from user-created content. However, just as important in driving this discussion is the affordability of computing power to effectively analyze this large corpus of content.
Today organizations are caught in the “Bigger is Better Syndrome” (BIBS). They build big infrastructures with big servers, big networks, big storage capacity, and, yes, big data. Companies talk about the terabytes and petabytes of data they have accumulated as though it were a badge of honor. I own a T-shirt that always garners a chuckle. It says, “Big People Are Harder To Kidnap.” That is an appropriate sentiment in this discussion on big data and big content. By accumulating and keeping more and more data, we get a sense of security; a sense that we will have what we need when we need it; and because of this, we will be able to make better decisions. It is the classic mindset of, “he who has the most wins.”
By accumulating and keeping more and more data, we get a sense of security; a sense that we will have what we need when we need it; and because of this, we will be able to make better decisions.
Within these ever-expanding haystacks of data live the needles of information required to manage our business, make good decisions, increase revenues, lower costs, and reduce risk. With nearly 80% of the information within organizations being unstructured content, Big Data is less the issue than Big Content.
Ken Bisconti, an IBM Executive focused on product and strategy for enterprise content management says, “Reports support that unstructured data is growing at a tremendous pace. Many organizations are struggling with the challenges of how to manage the data in many fields, including such issues as:
- How to capture it.
- How to put it into action with value for business.
- How to best achieve results.
- How to create savings.
- How to deal with regulatory compliance.
- Legal discovery.
- How to glean the best insight out of it.
- How to implement fraud detection.
- How to gain consumer insight, and on and on.”2
A bigger collection of content does not always translate into better operations. This ever-growing mountain of information can make it harder for executives, managers, and government officials to make decisions. No longer do they have the problem of making decisions with too little information. The information is often embedded within data, and some would argue the problem is too much information. We suggest that too much information is not the problem; rather, it is our lack of the ability to analyze and evaluate the massive amounts of data to find the required information. How do we associate the seemingly disparate bits of data into a comprehensive and meaningful view of a client, a project, or a process?
The challenge is, how do we gain insight? How do we improve our business or customer experience? The Rosetta Stone of this challenge is how to “multiply” the value of all this data, rather than simply trying to “add it up.” It is critical to be able to put “data” into a context, and it is “content” that provides context. This context allows us to turn data into information assets.
From where does all this data originate? It mostly begins life as content. Content drives business processes. Most business processes are initiated by content, result in the creation of content or both.
An example might be the procurement process. It starts with some form of requisition (a user needs something). The creation of that requisition (electronic or paper) initiates a procurement process. This process may result in creating several artifacts from requests for proposals to the proposals themselves, and in the end most likely results in a purchase order, a contract, or a contract amendment.
Managing this content through its life cycle is not cheap, but the cost is decreasing. In a Fast Company article, Steve Kerho notes, “It’s worth mentioning that the cost to create and support multiple pieces of content continues to decrease. That’s not to say good content is cheap–it isn’t. However, the process of conceiving, building, and deploying digital content becomes easier and cheaper each year.”3 We know, anecdotally, that as the cost of something goes down, we create more of it.
Structure to the Unstructured
All this content is largely amorphous. Word™ documents, Excel spreadsheets, photos, videos, PDF documents – all contain valuable information in an unstructured form. Even with full-text search capabilities, not having the information in an organized row and column-based format increases the cost of re-using that asset, and the likelihood the information will simply be recreated. Organizations spend significant resources in this race to categorize and classify information and to create and apply taxonomies to create this structure for unstructured content.
At Flamingo Services, we think of three types of content as illustrated below:
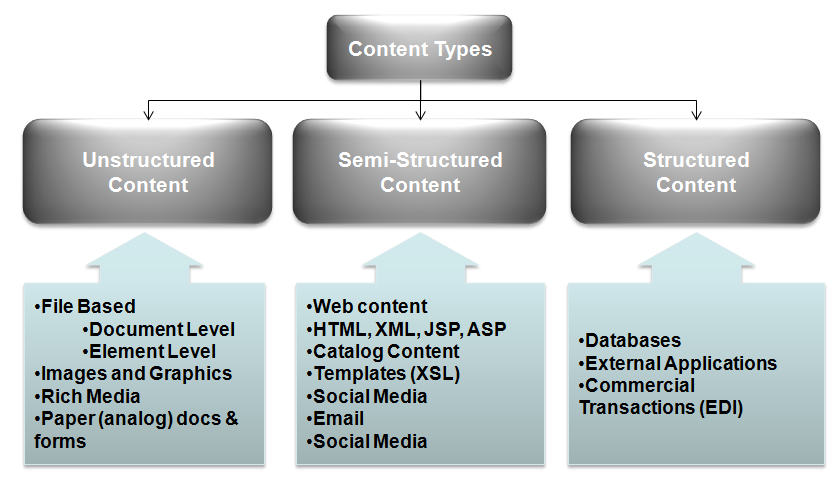
Content management over the past ten years has primarily attempted to bring structure to unstructured content by associating meta-data (and more recently tags) with the unstructured content. This approach allows the information contained in the content to remain in its meaningful context while providing some level of structure to support the associated business processes. These efforts do result in significant cost savings, productivity gains, and decreased risk, but they are not adequate for today’s information explosion. Basic business practices such as e-Discovery and compliance, which were hard, to begin with, are now becoming next to impossible because of the depth and breadth of data that must be analyzed.
In a 2011 “Digital Universe Study,” market analyst firm IDC predicted a 50-fold increase in data volumes by 2020. They break down big data issues into five primary issues.
- Variety: The data is in both structured and unstructured forms; ranges across the spectrum of e-mail messages, document files, tweets, text messages, audio and video; and are produced from a wide number of sources, such as social media feeds, document management feeds and, particularly in equipment sensors.
- Velocity: The data is coming at ever-increasing speeds — in the case of some agencies, such as components of the Department of Defense and the intelligence community, at millisecond rates from the various sensors they deploy.
- Volume: The data must be collected, stored, and distributed at levels that would quickly overwhelm traditional management techniques. A database of 10 terabytes, for example, is an order or two less than would be considered normal for a big data project.
- Veracity: The data collected at high speed can come with some “noise” along with it. To separate “true data” from noise is critical to making business decisions based on collected and analyzed data. Therefore, data in the context of its content is important.
- Value: The data can be used to address a specific problem or to address a mission objective that the organization has defined.
Enterprise content management (ECM) technologies must address these issues, and many solutions do, but they are not the complete answer. ECM strategies are important, but they will only be one component of the final solution to the challenges of big content and big data.
ECM strategies and technologies complement big data initiatives. With good governance and the application of some newer technologies, several critical goals can be accomplished:
De-duplication technologies reduce the number of objects in content repositories. This means less data and content to manage and reduces the risk that some content might be inappropriately deleted, while additional copies remain.
Auto-categorization solutions make using content management solutions more ubiquitous for end users. People no longer must remember to place objects in the correct folder or take the time to supply meta-data values.
Good governance practices mean implementing standard taxonomies so that content is more easily cataloged, searched, and re-tasked. Governance includes policies and procedures designed to ensure that important content is captured appropriately and managed in a legally defensible manner. It also means implementing a records management program which likely includes records management technology. These steps can help dramatically reduce the amount of content and data, which must be maintained and produced during a legal discovery or Freedom of Information Act (FOIA) response.
Content analytics components can help bring a semblance of structure to unstructured content by enhancing auto-categorization, but when properly applied, these technologies can produce a significant value proposition. This is accomplished through finding correlations and connections between data stores and content objects, that might otherwise be missed. In short, they can be a great help from a corporate intelligence perspective. Content analytics technologies can also help organizations more quickly identify areas of risk and opportunity, thus gaining a competitive advantage. One example of how content analytics can be used to make critical business decisions is “sentiment analysis”. Based on user-generated content rated content in social media, content can be harnessed to determine if a particular brand is trending up or down in the marketplace and corrective measures can be out in place accordingly.
Backfile Conversions-Still Part of the Process
Twenty-five years ago, micrographics was one technology that helped organizations store, preserve, and organize large amounts of information. Microfilm jacket systems allowed the creation of a folder structure, and computer-assisted retrieval systems (CAR) allowed users to locate film images faster, by indexing the contents of the film and associating the index with a specific image. There were costs. This included not only the actual costs of filming, but also preparing and organizing the documents, and entering the index information. Organizations at the time wrestled with these costs about converting their large collections of paper files (backfile conversion).
When document imaging (scanning) and the first document imaging systems were introduced, organizations were faced with the same value proposition decisions concerning the scanning of their existing backfile. Today, most documents are “born digital,” and organizations work to keep them in digital form, but there is still a “backfile” issue to address. As we have noted, organizations have accumulated large collections of electronic documents in poorly organized file shares and SharePoint sites.
Most organizations would simply not find it cost-effective to pay for people to look through these existing file shares and organize and index the content.
While we no longer have the costs of scanning or microfilming documents, there is still the cost of indexing and organizing these large collections. Some tools can help automate the process, and their ability to analyze content is rapidly improving. Most organizations would simply not find it cost-effective to pay for people to look through these existing file shares and organize and index the content. Tools such as Active Navigation and IBM’s Content Classifier products can help make this task more cost-effective, but there are still costs and risks, which must be considered as part of any big content management strategy.
These technologies work by identifying and removing redundant, obsolete, and trivial objects (ROT) from the content stores. They then automate the classification/categorization of lower value content, while presenting high-value content for review and additional indexing and categorization.
In a recent Gartner report, Analyst Alan Dayley writes, “Explosive, unstructured data growth is forcing IT leaders to rethink data management. IT, data, and storage managers use file analysis to deliver insight into information from the data, enabling better management and governance to improve business value, reduce risk, and lower management cost.” The report goes on to note, “Organizations should review the scope of their unstructured data problems by using file analysis (FA) tools to understand where dark unstructured data resides and who has access to it.”4
The Active Navigation and IBM products mentioned here, along with others, can help organizations analyze, manage, and classify their Big Content. In short, they help to address the newest “backfile” challenge. But most important, these technologies can be used to automate the classification and categorization of electronic content going forward and make the process ubiquitous to end-users.
Big Content Is Smarter Content
Organizations have often made large investments in ECM solutions, which not only support the basic governance of the content but also support business processes through workflow and shared data with other line-of-business applications.
While content has been getting bigger, these technologies are helping it become smarter. What we are seeing in the realm of content management in relation to big data is less revolutionary and more evolutionary.
Since their earliest beginnings, relational databases have been developed to meet business requirements, and that has also been true for web application frameworks and content management systems. For obvious reasons, organizations and vendors have developed functionalities for specific use cases that are evolving but remain relevant today.
Today’s technologies such as semantic text analytics, business intelligence, and data warehousing all bring new and greater opportunities for content management solutions. However, to take advantage of these opportunities, content management technologies will require integration with existing content-centric applications, all without rewriting them.
All IT infrastructure and technology platforms must be prepared for this kind of processing scale. Organizations should consider ECM solutions as platform decisions. As Eric Barroca writes in an article for Fierce Content Management, “The time for out-of-the-box CMS applications has passed; now each project needs the ability to build a solution that can meet specific needs and individual requirements for a smarter approach to the way content applications work versus their predecessors.”5 There must be fewer specialized “point solutions,” as each of these creates its new haystack.
ECM will not be reinvented; rather, ECM architects will develop and implement well-designed platforms.
Traditional components of ECM, such as workflow and content life cycle management are becoming more flexible. They are adapting to today’s more collaborative work environments. These smarter architectures and adaptive workflows, combined with deeper integration with core business applications, are refining the way intelligence is brought to content.
The results of Big Data and smart content will be to push more enterprise content management towards technical features such as software interoperability, extensibility, and integration capabilities. To achieve this interoperability, it is necessary to develop clean and adaptive architectures flexible enough to evolve as new standards arise.
Older legacy ECM suites will have a harder time leveraging these new opportunities, but most of the major ECM players have been moving to more modular and extensible platforms. ECM will not be reinvented; rather, ECM architects will develop and implement well-designed platforms that will permit organizations to build solutions that not only provide required end-user features but will also remain flexible and interoperable as part of an enterprise strategy.
Architect to Address Big Content
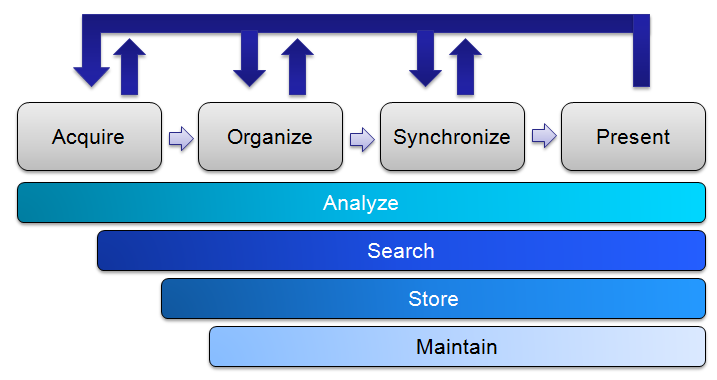
Managing big data or big content is about how the information is funneled into the organization, moved through the organization’s business processes, and then presented as a product. To be scalable, any big content management solution must be able to perform all the following operations:
Acquire – In the world of content management, this is often considered the “capture” process, and includes all the different ways content is added to the repositories. This might include saving files; receiving faxes; scanning documents or completing an electronic form.
Organize – This is closely related to capture and is sometimes referred to as “preprocessing.” This operation involves identifying content. This could include adding or supplementing metadata; adding tags; indexing for full-text capabilities. Some of these steps might be manual but should be automated to the extent possible.
Synchronize – This operation activates content in the business processes. Content and line of business data may be combined, and workflows might be initiated. Content may be correlated and associated with supplemental documents, and items may be reviewed and approved.
Present – Often referred to as publishing, this is about how data and content might be presented to constituent groups within an appropriate context. It might include printing out correspondence, generating an email, executing a contract, or adding content to a website. In this operation, an information consumer might see content objects combined with system data to enhance the usability of data and content through a process-specific context.
Analyze – This is a supporting process that enhances the value of the information by extracting meaningful content in context, associating it with other relevant content, and presenting the information in different ways to enhance the organization’s operations. This analysis allows the organization to leverage big data and big content by re-using the information in different contexts. Cloud-based computing capabilities can aid in this analysis by allowing organizations to temporarily scale for specific projects and return to a steady-state.
Search – If the information is meticulously organized and analyzed, the needle in the haystack becomes vastly easier to locate. Modern analytical technologies can present usable, process-specific information to users from various perspectives, thus allowing users to find answers in creative and previously unavailable contexts.
Store – This sounds like a simple operation often addressed through the purchase of enterprise storage devices, and indeed, such devices have their place. However, users tend to store information in a range of locations and various devices. The challenge becomes one of how to either acquire all the information assets and move them to a central repository, or how best to store and manage the information in-place.
Maintain – Information is a key asset for every organization. Businesses can fail due to a loss of their information. However, maintenance goes beyond creating backups and maintaining high-availability computing systems. There is also a governance component of this process. Organizations have a legal obligation to maintain systems of record, to keep content for legally required retention periods, and assure that content is deleted/destroyed from these systems in a timely and appropriate way.
In the representation of these processes as shown below, data and content have a life cycle. If well implemented, ECM systems allow information to be re-purposed. Not only is new information being constantly added, but it is also included in the analysis of existing information, clarifies a decision point, or indicates that more information or analysis might be needed. Information from one business process can be used to enhance additional business processes.
Amazon.com is an amazing example of this. If you have ever ordered from them, you know that you will be presented with “suggestions” when you visit their site, and you’ll get emails with suggestions. They capture and aggregate massive amounts of user information – not just about what you have viewed and purchased, but also what others, who viewed or purchased items like yours, have viewed. This data is all aggregated from a range of internal back-end systems.
Flamingo Services has adopted a common Information Lifecycle Governance (ILG) Technology Reference Model to help us understand what an ECM architecture might include.
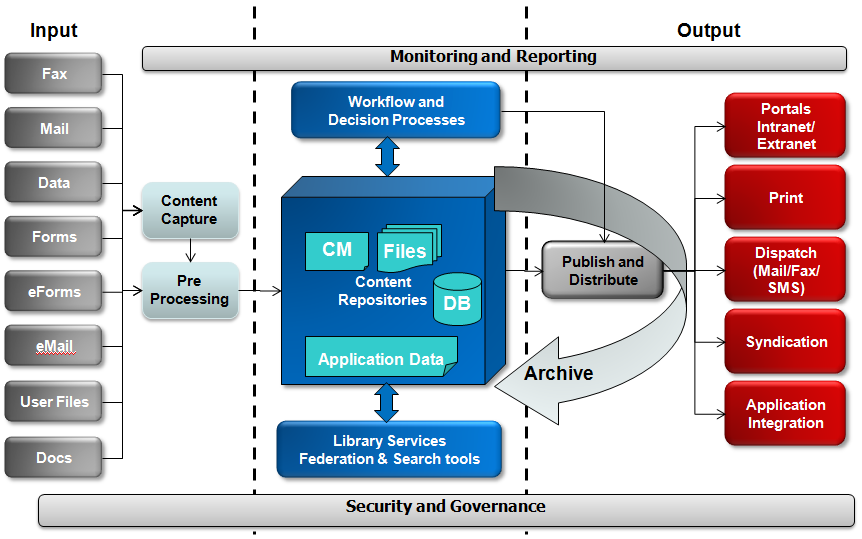
The ILG model maps very closely to the Big Content Operations Model discussed earlier. There is an input channel, and an output or presentation layer, combined with the various technology components which support the business processes. This includes a content repository, databases, workflow components, and governance and reporting tools.
Summary
We live in a world where big data is here to stay.
Google uses big data to try to predict what products or services might interest you next, where you are going, and what you will do when you get there. Other organizations use Big Content Analytics to identify potentially fraudulent activity, decrease risk, and decrease time to market (as examples).
Big Data and Big Content are not better or worse they just “are.” It can overwhelm an organization and create decision paralysis, or it can be exploited to create new opportunities and improve business activities. The side your organization lands on will depend on how you plan for and execute on a long-term content management strategy. Such a strategy can provide the following benefits now, and in the future:
- Decreased costs per transaction.
- Better decision-making.
- Lower IT costs.
- Decreased risk and lower litigation costs.
- Improved vetting and fraud prevention.
- Faster time-to-market for new opportunities.
- Improved employee performance and satisfaction.
- Enhanced customer focus and interactions.
We live in a world where big data is here to stay. Your success, much like Google’s, will hinge on your organizations’ ability to re-imagine how you use the data available to you, to put it into new contexts; in short, how your organization turns Big Data into Big Content.
Flamingo Services has more than 30 years of experience helping organizations plan for the future and execute enterprise content management strategies. We’ve worked with large corporations and government clients, including Harley Davidson Financial Services, one of the largest consumer credit institutions in the U.S., the U.S. Department of State, the U.S. Army, the U.S. Air Force, the Department of Homeland Security, and the National Institutes of Health.
At Flamingo Services, we know how to turn Big Data into Big Content for greater effectiveness, improved profits, and better decision making. Let us show you how.
About Flamingo Services
For over 30 years, Flamingo Services has been providing proven methodologies, expertise and award-winning technologies, services, and powerful, flexible, and scalable ECM solutions to leading public sector and commercial clients. Flamingo Services’ solutions allow clients to use information as a strategic asset and enable them to make better decisions, improve service levels, reduce risk, and manage compliance. Combining leading technologies with Flamingo Services service offerings, clients can identify, consolidate, standardize, and modernize their infrastructures to transform data into valuable assets.
- International Data Corporation Forecast [↩]
- Big Data, Social, Analytics, Content Management Everywhere – IBM’s Ken Bisconti,” Silicon Angle, John Cossareto, October 2012. [↩]
- “Before Big Data Comes Big Content, Fast Company, Steve Kerho. [↩]
- Innovation Insight: File Analysis Innovation Delivers an Understanding of Unstructured Dark Data, Alan Dayley, Analyst, Gartner, March 28, 2013. [↩]
- “Big Data and Smart Content: New challenges for content management application,” Eric Barroca, Fierce Content Management, December 19, 2011. [↩]